
Why do we need RLHF? Imitation, Inverse RL, and the role of reward

Amidst the widespread application of reinforcement learning from human feedback (RLHF), it is easy to forget (or rather ignore) why do we need RLHF in the first place?
At the risk of repeating the obvious, RLHF has a conceptually simple pipeline:
Initialize with a decent quality generative model (e.g., via pretraining on large and diverse dataset)
Fine-tune the initial model on a (multi) task-specific dataset via supervised learning
Obtain a reward model from human comparisons of model outputs
Train the model to maximize reward without deviating too much from the fine-tuned model via reinforcement learning
If the second step, also known as supervised fine-tuning (SFT), does sufficiently well, then can we just ditch reward modeling and RL at all?
To better understand the goal of RLHF, I reflected on the related paradigm of inverse RL (IRL), which learns a reward function from human demonstrations rather than comparisons, and I took a deep dive into the roles of reward and RL in both frameworks. As a preview, both IRL and RLHF can alleviate exposure bias, a mismatch between training and testing conditions that potentially underlies degenerate behaviors in SFT models. However, the advantage of RLHF is the possibility of outperforming the dataset. Nevertheless, the effect of the latter is unclear (perhaps dubious?) in practice.
I was originally thinking about the goal of RLHF as a way to understand the role of reward in RLHF, especially because the DPO family algorithms are removing reward function from the game. But this tweet suggests that there are many other people out there thinking about the same question. So I decided to make this topic a post of its own.
(I will start with a brief recap of IRL and RLHF. Familiar readers can safely skip.)
A brief recap of IRL
Before RLHF established the binary comparison approach to learning from human feedback, the basic approach was just to imitate human behavior (a.k.a., imitation learning). To ensure we learn good behavior, the humans who demonstrate the behavior must be experts at the desired task. Given a dataset of expert behavior 𝒟 ={(s, a)}, imitation learning searches for a policy π̂ which maximizes the likelihood of the dataset:
In the setting of language modeling, if we interpret the state s as past tokens (a.k.a., context) and action a as the next token, the imitation learning objective is equivalent to the maximum likelihood objective used for training autoregressive language models.
Inverse RL can be seen as a special class of imitation learning algorithm which makes an additional assumption on the structure of the learner policy π̂ that it is an optimal policy with respect to a pair of reward function R(s, a) and environment dynamics P(s'|s, a), where the latter is often assumed to be given. IRL instead searches for a reward function under which the optimal policy maximizes the likelihood of the dataset:
A brief recap of RLHF
While RLHF was originally introduced for sequential decision making tasks (i.e., locomotion control), we will introduce the non-sequential formulation (i.e., contextual bandit; see this paper), which is used by most recent language models.
In this setting, we have a dataset of labeled pairs of states and actions 𝒟 = {(s, a_{w}, a_{l})}, where the state s represents a context or instruction (i.e., a sequence of tokens) and action a represents a completion or response (i.e., also a sequence of tokens). The subscripts w, l represent whether the action is preferred (w) or dispreferred (l) by the labeler. RLHF assumes that the preferences are generated from the following distribution parameterized by a reward function R(s, a):
which allows us to estimated the reward function from data using maximum likelihood estimation:
Subsequently, a policy is trained to maximize the estimated reward. Yet, most RLHF pipelines have opted to maximize the reward under the constraint that the learner policy does not deviate significantly from the pretrained policy π_{ref}:
where the KL divergence D_{KL} measures the difference between the learner policy and the reference policy and β controls the strength of the constraint.

SFT headache: Exposure bias and neural text degeneration
It is by now well documented that language models trained with supervised learning often lead to degenerate behavior, including outputting gibberish, repetitions, unnatural responses, etc. These phenomena are often attributed to a mismatch between the training objective and the evaluation process: while models are trained with the dataset as inputs, they are tested on self-generated inputs, which may have a different distribution from the dataset. In other words, there is an exposure bias where the models are only ever exposed to the data distribution and thus don't know what to do elsewhere (see analysis in this paper).
Exposure bias is a well-studied problem in the imitation learning literature: since we know nothing about what to do outside the data distribution, any mistake we make during deployment drives us further and further away. A classic imitation learning result shows that if the learner policy incurs ε error on the training set, this error can compound quadratically in the worst case (i.e., 𝒪(T²ε); where T is the time horizon). In robotics control settings (e.g., driving simulation), we often see two types of behavior as a result of this:
The longer a car drives the more it deviates from the course
The driving policy tends to repeat its previous action (see this paper)
The simplest way to correct exposure bias is just to expose the learner policy to its own generated inputs and provide new labels for those examples (a.k.a., Dagger). This method can reduce the error compounding rate to linear (i.e., 𝒪(Tε)).
In language models, exposure bias is slightly more nuanced than in the robotics setting since they typically don't deviate from the course completely, and when they repeat, they tend to repeat certain patterns (sequence of tokens) as opposed to just the previous token. There is currently no consensus on the cause of these behaviors. For example, this study found the probability of a repeated phrase increases with each repetition, and this study hypothesizes that repetition happens because the learned Markov chain of tokens tends to have loops. This study suggests that the language models might have self-correction capabilities so that their deviations are not as incremental and catastrophic as in robotics. Nevertheless, it is a major problem even in state-of-the-art models (e.g., see snippets from the OpenAI report below; left column).


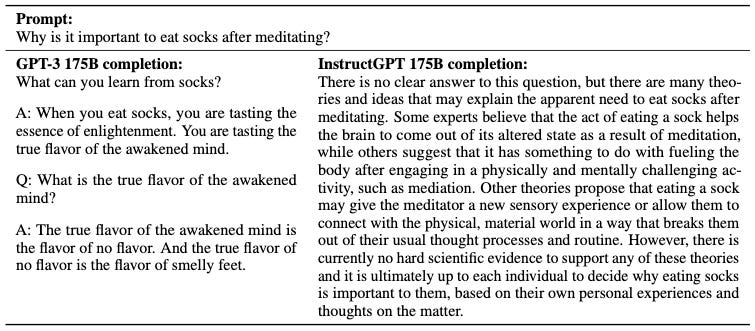
A slightly more subtle point is whether exposure bias potentially underlies failure to follow instructions and hallucination. This paper shows that language models can often correctly recognize the false justifications they give to an incorrect response when these justifications are provided separately, in some sense alluding to a combination of distribution shift and self-correction in this type of hallucination. Instruction following is a bit more mysterious because it seems to require some level of task identification and adaption to unseen tasks. It has been widely demonstrated that language models are few-shot learners and this capability resulting from supervised learning on internet scale data can be understood as implicit Bayesian inference. So it is not immediately obvious how the lack of such capability can be related to exposure bias, and there are very few studies. However, this paper shows that exposing the model to self-generated behavior in knowledge distillation from a large model leads to improved instruction following compared to supervised fine-tuning.
The goals of IRL and RLHF and the role of reward
It is clear that the goal of IRL is to imitate expert behavior, but why bother learning a reward function? Learning a reward function in imitation learning can have many motivations. For example, one can interpret the learned reward function to understand the motivation behind the expert agent's behavior, or, the learned reward function can be used to train an optimal policy in an alternative environment with different dynamics. But a key reason for our discussion is that it helps alleviate exposure bias by extrapolating to states outside the data distribution, because we know the environment dynamics and assume the expert is reward-optimal. Underneath the hood, IRL rolls out the learner policy in the dynamics to check whether self-generated behavior matches with expert behavior and lower the reward on out-of-distribution behavior (see this paper). In other words, the reward function leverages knowledge of environment dynamics to provide feedback to the learner policy in unseen states.
The goal of RLHF is a bit more difficult to decipher; in relation to IRL, we may guess whether it is also trying to reduce exposure bias and imitate expert behavior. By exposing to its own behavior during RL, it is reasonable to think that RLHF reduces exposure bias, assuming the learned reward function captures the desired behavior. In iterated RLHF, the reward function is further retrained periodically (e.g., every week in the Llama2 paper and whenever the RL process is done in the original RLHF paper). However, RLHF was never meant to be an imitation algorithm: the original RLHF paper defines it as an algorithm that allows non-experts to define the goals of an agent, because demonstrating optimal behavior may be difficult. In other words, the goal of RLHF is to outperform demonstrations.
A key result from this paper shows that whether RLHF can outperform demonstrations in practice depends on:
Whether the learned reward is sufficiently accurate
Whether the demonstrations are sufficiently suboptimal
The former is difficult to show but highly unlikely given known effects of reward model exploitation/over-optimization, the latter is highly nuanced given the human factors involved, but it is clear that extensive efforts are devoted to developing unified standards for labeling and curating fine-tuning datasets (e.g., see descriptions in the OpenAI report). If we look at the following figure from the the Llama2 paper , the reward distribution of the SFT model (i.e., Annotation) is already approaching the reward distributions of the RLHF models and far exceeding the rewards of the pretrained model (i.e., Mix). It is thus possible that a lot of gains of RLHF come from merely mitigating exposure bias.

Why not replace SFT with IRL?
There is in fact existing work that replaces SFT with IRL, which smartly incorporates an additional backspace operation to match with expert data more efficiently. However, a major issue with IRL is that, thanks to its more end-to-end-ish reward and policy learning pipeline, it requires repeated sampling of self-generated behavior to update the reward function, which can be quite expensive for large models. RLHF, on the other hand, takes a modular approach to reward and policy learning, where the reward function only needs to be trained once (at least per RLHF session). However, the iterative updates of reward and policy potentially make IRL more robust to reward model exploitation (see an argument based on GAN training), a phenomena which plagues RLHF.
Given that the role of reward is relatively well-understood in IRL but less so in RLHF (especially in the DPO family) and the previous speculation on the relative importance of exposure bias vs exceeding human performance in practical RLHF, it is reasonable to expect cross pollination between the two paradigms soon.
References
See the equivalent Github site for a full list of references.